
ChatGPT 5.2 Is Finally Here: What’s New, Why It’s Better, and How It Stacks Up vs Gemini 3 and Claude
TL;DR Summary
GPT-5.2 (Instant / Thinking / Pro) launched Dec 11, 2025 for ChatGPT paid plans and via API, positioned as OpenAI’s best model family for everyday professional work. (OpenAI)
The headline claim is reliability + “knowledge work” execution: GPT-5.2 Thinking beats or ties human experts on 70.9% of GDPval comparisons (OpenAI’s structured knowledge-work evaluation). (OpenAI)
Benchmarks show meaningful jumps in coding (SWE-Bench Pro/Verified), science reasoning (GPQA Diamond), abstract reasoning (ARC-AGI-2), and long-context retrieval (MRCRv2 needles). (OpenAI)
Gemini 3 still looks extremely strong on high-end reasoning (e.g., GPQA, ARC-AGI-2 in “Deep Think”), while Claude Opus 4.5 remains a top pick for real-world coding + computer use (SWE-bench Verified, OSWorld). (blog.google)
Strategically, OpenAI frames GPT-5.2 as the “code red” response to Gemini momentum—while also saying the model was in development for months and the “code red” focus should end by January (per Bloomberg/Verge reporting). (Reuters)

What OpenAI Actually Shipped (ChatGPT 5.2 Instant, Thinking, Pro)
OpenAI is shipping GPT-5.2 in three variants designed around trade-offs: speed, structured reasoning, and maximum accuracy. In ChatGPT, they’re branded as ChatGPT-5.2 Instant, ChatGPT-5.2 Thinking, and ChatGPT-5.2 Pro. In the API they map to gpt-5.2-chat-latest, gpt-5.2, and gpt-5.2-pro. (OpenAI)

GPT-5.2 variants (what they’re for)
GPT-5.2 Instant
Best for: fast information-seeking, writing, lightweight workflow help
What changes in practice: lower latency and “workhorse” behaviour for day-to-day tasks
GPT-5.2 Thinking
Best for: structured work (analysis, planning, coding, long documents)
What changes in practice: higher reasoning effort with stronger tool-use and long-context retrieval
GPT-5.2 Pro
Best for: highest-stakes tasks where accuracy matters most
What changes in practice: highest cost tier; supports adjustable reasoning, including xhigh effort for difficult questions

OpenAI’s positioning is explicit: GPT-5.2 is described as better at creating spreadsheets, building presentations, writing code, perceiving images, and understanding long context.
What’s New in GPT-5.2
“Professional work” performance finally becomes a first-class target
The standout metric OpenAI wants the market to remember is GDPval (44 occupations, “well-specified” knowledge work tasks). GPT-5.2 Thinking beats or ties human experts 70.9% of the time (ties allowed), up from 38.8% for GPT-5.1 Thinking. (OpenAI)
OpenAI and third-party coverage also emphasise “economic value”: Business Insider reports OpenAI’s claim that GPT-5.2 produced GDPval outputs at >11× the speed and <1% the cost of expert professionals (with human oversight). (businessinsider.com)
Why this matters: a lot of “AI model hype” collapses when you try to run real workflows end-to-end (inputs messy, constraints real, outputs need formatting). GDPval is OpenAI’s attempt to measure work completion, not just clever answers.
Spreadsheets + investment banking-style modelling got a measurable bump
OpenAI includes an internal benchmark for “investment banking spreadsheet tasks”: GPT-5.2 Thinking scores 68.4% vs GPT-5.1 Thinking 59.1%; GPT-5.2 Pro is 71.7%. (OpenAI)
Business Insider adds colour: examples include building three-statement models and LBO models with formatting/citations, and calls out the lift as meaningful for spreadsheet-heavy roles. (businessinsider.com)Long-context retrieval improved sharply (not just “bigger context” marketing)
The strongest evidence is OpenAI’s MRCRv2 “needles in a haystack” style eval. GPT-5.2 Thinking is materially higher than GPT-5.1 Thinking across ranges up to 128k–256k contexts (e.g., 77.0 vs 29.6 at 128k–256k). (OpenAI)
Translation into reality: fewer “it forgot what was on page 73” failures when summarising long reports, contracts, or multi-file project context.
Tool-use and agentic workflows got more credible
OpenAI reports improvements on tool-use benchmarks like BrowseComp, Toolathlon, and Scale MCP-Atlas (tool orchestration). (OpenAI)
This aligns with what professionals actually feel day-to-day: models are moving from “answering” to executing (multi-step plans, verification, calling tools, iterating).Hallucinations and “answers without errors” improved (two different signals)
OpenAI reports higher “ChatGPT answers without errors” both with and without search (e.g., 93.9% vs 91.2% with search). (OpenAI)
Meanwhile, broader coverage highlights reductions in hallucinations/false claims, though phrasing differs by outlet (e.g., “30% off false claims” reporting in TechEBlog, and a separate Wired framing that cites a 38% drop in hallucinations). (TechEBlog)
Practical view: for enterprises, “slightly smarter” is less important than fewer costly mistakes in documents, spreadsheets, or code changes.
The Benchmarks That Define GPT-5.2 (and what they mean)
Benchmarks aren’t the whole story, but they do signal where a model family is investing: coding agents, scientific reasoning, abstract reasoning, and long-context work.


GPT-5.2 vs Gemini 3 vs Claude: Who wins what?
There is no single winner. The more accurate conclusion is: the frontier is splitting into specialisations.
Gemini 3: still a serious benchmark monster
Google’s Gemini 3 Pro reports: SWE-bench Verified 76.2%, GPQA 91.9%, and Humanity’s Last Exam (HLE) 37.5% (no tools). Google’s “Deep Think” mode reports even higher (e.g., GPQA 93.8%, ARC-AGI-2 45.1%). (blog.google)
Interpretation:
Gemini remains exceptionally strong in high-end reasoning (especially in Deep Think mode).
The key question is productisation: will users consistently pay the latency/compute cost of “Deep Think” style inference for everyday work?
Claude Opus 4.5: coding + computer use leadership signals
Anthropic positions Claude Opus 4.5 with 80.9% on SWE-bench Verified and 66.3% on OSWorld (computer use). (anthropic.com)
Interpretation:
If your primary KPI is “ship reliable code” or “operate tools/UI”, Claude stays a very strong contender.
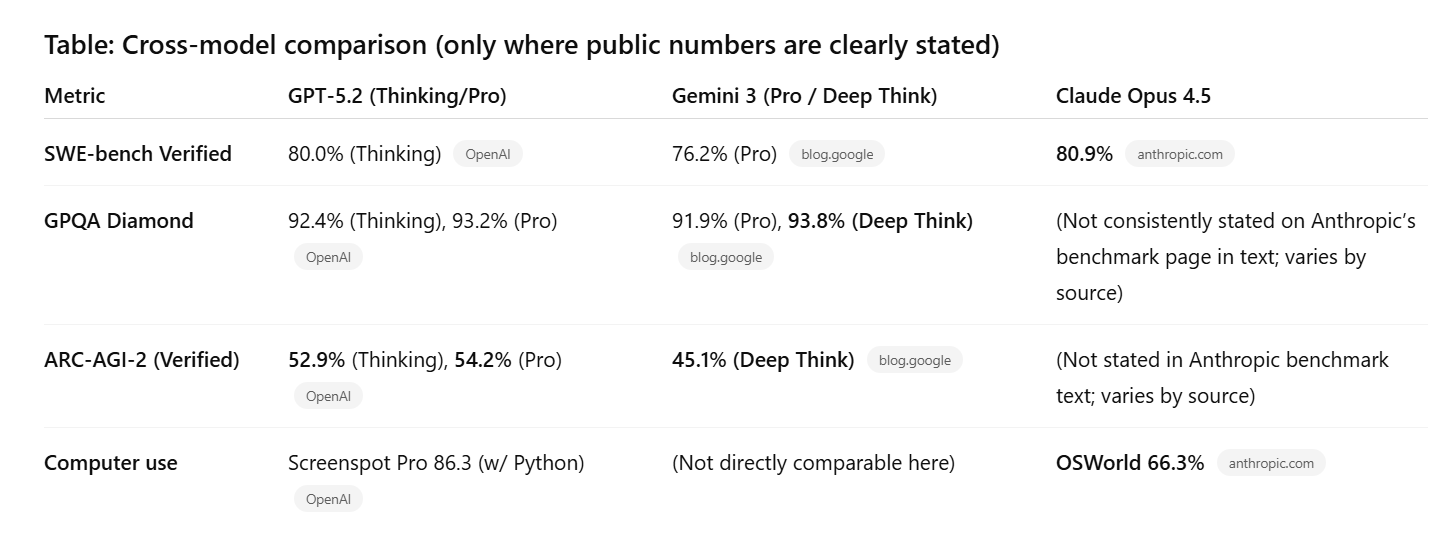
Bottom line: GPT-5.2’s differentiator is less “I top every benchmark” and more “I complete professional workflows with fewer errors”—and OpenAI now has benchmark scaffolding (GDPval + tool-use + long-context) to support that positioning. (OpenAI)
Pricing, Deployment, and the “Real Cost of Quality”
OpenAI’s API pricing shows a deliberate segmentation: Thinking is relatively accessible; Pro is premium.
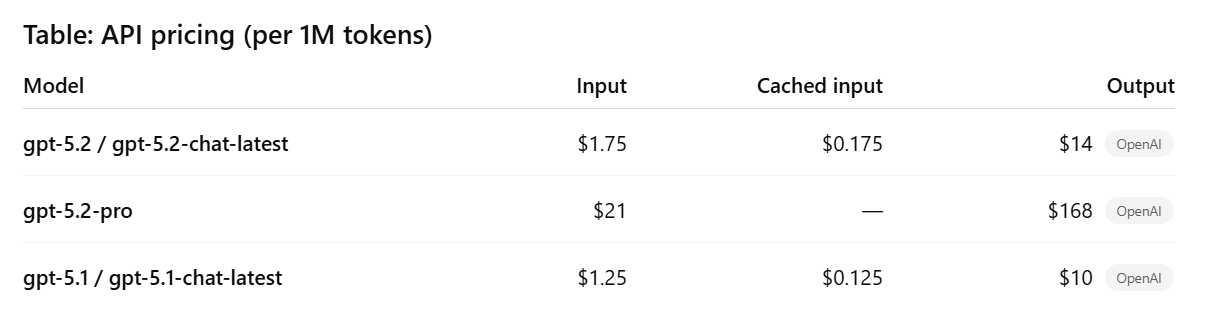
OpenAI argues that despite higher per-token cost, token efficiency can reduce “cost to reach a given quality.” (OpenAI)
Recommendation for teams: treat Pro as your “closing model” (final checks, critical deliverables), and Thinking as your “workhorse” for planning, drafts, and multi-step execution.
Is Sam Altman’s “Code Red” Ending in January 2026?
The GPT-5.2 launch lands inside a competitive narrative: OpenAI issued a “code red” internally to accelerate ChatGPT improvements after Gemini 3’s strong showing. Reuters reports Altman said Gemini 3 had less impact on OpenAI’s metrics than feared, and confirms GPT-5.2’s roll-out across paid ChatGPT plans (Instant/Thinking/Pro) plus API availability. (Reuters)
From the CNBC briefing you shared (plus corroborating reporting): OpenAI’s leadership framed “code red” as a resource reallocation and prioritisation mechanism rather than a rushed build, and Altman expects OpenAI to exit code red by January; Bloomberg also reports Altman expects to exit code red by January “in a very strong position.” (Bloomberg). The Verge similarly reported the code-red period would conclude around the January timeframe (citing WSJ). (The Verge)
Also notable: Reuters reports Disney announced a $1B investment tied to OpenAI collaboration, adding to the sense that GPT-5.2 is not just a model release, it’s part of a broader commercial scaling push. (Reuters)
Key Takeaways
GPT-5.2 is a credibility play. It’s optimised for fewer mistakes and stronger workflow completion, not just clever chat. (OpenAI)
Gemini 3 remains the most dangerous competitor in pure benchmark optics, especially with Deep Think results, but product UX/cost will determine real adoption. (blog.google)
Claude stays the “coding + computer use” specialist, and for many teams that’s still the highest-leverage domain. (anthropic.com)
The macro story: the “AI model war” is turning into a work platform war, where the winning model is the one that integrates into daily professional workflows most reliably.
ChatGPT 5.2 Launch FAQs
What is GPT-5.2 and when was it released?
GPT-5.2 is OpenAI’s latest frontier model family (Instant, Thinking, Pro) released on December 11, 2025, rolling out to ChatGPT paid plans and available via the API. (OpenAI)
What are GPT-5.2 Instant, Thinking, and Pro?
They’re variants tuned for different trade-offs: Instant for speed, Thinking for structured reasoning and long tasks, and Pro for highest accuracy with higher cost and configurable reasoning. (OpenAI)
What is GDPval and why is it important?
GDPval is OpenAI’s evaluation for “well-specified” professional knowledge work across 44 occupations. OpenAI reports GPT-5.2 Thinking beats or ties human experts 70.9% of the time (ties allowed). (OpenAI)
Is GPT-5.2 better than GPT-5.1?
On OpenAI’s published benchmarks, GPT-5.2 shows significant gains in GDPval, GPQA Diamond, ARC-AGI-2 Verified, long-context MRCRv2 retrieval, and several tool-use metrics. (OpenAI)
Is GPT-5.2 better than Gemini 3?
It depends on the task. Gemini 3 Pro and “Deep Think” report very high scores on GPQA and ARC-AGI-2, while GPT-5.2 shows very strong gains in professional workflow evaluation (GDPval) and large improvements across long-context and tool-use. (blog.google)
Is GPT-5.2 better than Claude Opus 4.5 for coding?
Claude Opus 4.5 reports 80.9% SWE-bench Verified, while GPT-5.2 Thinking reports 80.0% SWE-bench Verified—they’re extremely close on that metric. For agentic coding, OpenAI also highlights SWE-Bench Pro (55.6 for GPT-5.2 Thinking). (OpenAI)
What is SWE-bench Verified vs SWE-bench Pro?
SWE-bench Verified is a widely used real-repository coding benchmark. OpenAI also reports SWE-Bench Pro as a more “agentic coding” oriented benchmark set in their reporting. (OpenAI)
How good is GPT-5.2 at long documents and long context?
OpenAI reports strong improvements on MRCRv2 long-context retrieval tasks across increasing context sizes, including up to 128k–256k ranges. (OpenAI)
What does “code red” mean at OpenAI?
“Code red” was reported as an internal priority push to focus resources on improving ChatGPT in response to competitive pressure, particularly after Gemini 3’s release. Reuters confirms the code-red framing and notes Altman said Gemini 3 had less impact on metrics than feared. (Reuters)
When will OpenAI exit “code red”?
Based on the CNBC reporting you shared and corroborating coverage, Altman expects OpenAI to exit “code red” by January; Bloomberg reports this expectation explicitly. (Bloomberg)
How much does GPT-5.2 cost in the API?
OpenAI lists $1.75 / 1M input tokens and $14 / 1M output tokens for GPT-5.2 (Thinking/Instant mappings), with gpt-5.2-pro at $21 input and $168 output per 1M tokens. (OpenAI)
What’s the SEO/AEO impact of GPT-5.2?
As models get better at executing professional tasks and summarising long context, publishers and brands need content that is structured, source-backed, and uniquely informative to earn AI citations and visibility in answer engines. (Use clear headings, tables, and FAQs—exactly like this format.)
About Modi Elnadi
I’m Modi Elnadi, a London-based AI-first Growth & Performance Marketing leader and the founder of Integrated.Social. I help brands win in the new search landscape by combining PPC (Google Ads / Performance Max) with AI Search, SEO + AEO/GEO so you don’t just rank on Google you show up in answer engines like ChatGPT, Gemini, and Perplexity when buyers ask high-intent questions.
If this article helped you, I’d genuinely love to connect. Reach out on LinkedIn (Modi Elnadi) with what you’re building (or what’s broken), and I’ll share a practical angle on where you’re likely leaving performance on the table, whether that’s prompt-led content engineering, AI visibility, or paid media efficiency. If you reshare, please tag me and I’ll jump into the comments.
References
OpenAI — Introducing GPT-5.2: https://openai.com/index/introducing-gpt-5-2/
Google — Gemini 3 benchmarks: https://blog.google/technology/ai/introducing-gemini-3/
Anthropic — Claude Opus 4.5 benchmarks: https://www.anthropic.com/claude/opus
Reuters — GPT-5.2 launch + code red context: https://www.reuters.com/technology/openai-launches-gpt-52-ai-model-with-improved-capabilities-2025-12-11/
Bloomberg — code red exit by January: https://www.bloomberg.com/news/articles/2025-12-11/openai-unveils-more-advanced-model-as-race-with-google-heats-up
Business Insider — GDPval speed/cost framing + internal IB tasks: https://www.businessinsider.com/openai-gpt-5-2-update-release-2025-12
TechEBlog — launch roundup + “30% off false claims” claim: https://www.techeblog.com/openai-gpt-5-2-features-release/